YOLO-Assisted Object-Centric Preprocessing Improves Family-Level Shell Classification on Real-World User Uploads
Published on: June, 2026
Abstract
Real-world shell identification differs substantially from curated image classification because user-submitted photographs vary in background, object scale, image quality, shell count, and taxonomic relevance. This study evaluated whether YOLO-assisted object-centric preprocessing improves family-level shell classification in the IdentifyShell application. A temporally defined dataset of 1,004 user uploads from the first half of 2025 was processed through two paired prediction flows: the standard pipeline using the original image, and a YOLO-assisted pipeline that detected shell instances, selected a crop, replaced the background, and passed the transformed image through the same downstream domain router and family classifier. YOLO produced a correct shell-localization or correct no-object outcome in 85.3% of images. Family-level accuracy increased from 33.4% on original images to 44.1% after YOLO preprocessing, while top-3 accuracy increased from 52.3% to 58.0%. Gains were strongly domain-dependent: field images improved from 22.7% to 37.1%, and multi-object images from 33.1% to 51.6%, whereas studio images decreased slightly from 84.8% to 78.3%. The main mechanisms were segmentation-assisted domain normalization, crop-based shell magnification, and reduction of background/context bias. YOLO preprocessing shifted many field images into home-like or studio-like visual domains and increased average shell occupancy in the classifier input. However, the method also introduced upstream failure modes, including missed shells, wrong-object crops, very small shells, and crop clipping. Agreement between original and YOLO-assisted predictions identified a higher-reliability subset, especially when combined with confidence thresholds. These results show that object-centric preprocessing is a useful robustness layer for heterogeneous shell uploads, but should be deployed with confidence gating, crop-quality checks, and user-facing image-quality feedback rather than treated as a universally safe replacement for original-image prediction.
Introduction
Image-based taxonomic identification is increasingly used to support biodiversity observation, collection management, citizen-science workflows, and expert triage. In malacology and conchology, shell photographs are particularly attractive for automated identification because many diagnostic characters—overall outline, sculpture, aperture shape, spire height, colour pattern, ribbing, and ornamentation—are visually accessible. However, the same biological richness that makes shells useful for morphological taxonomy also makes automated classification difficult. Closely related taxa may differ by subtle morphological features, while unrelated taxa may converge in shell form because of similar ecological or functional constraints. For this reason, shell recognition is best understood as a fine-grained biological image-classification problem rather than as a generic object-recognition task.
Most deep-learning classifiers are developed and evaluated under conditions that are more controlled than those encountered in operational use. Images used for model training or benchmarking are often curated, object-centred, and biased toward visually informative examples. In contrast, a public identification system receives images produced by non-specialist users under uncontrolled conditions. User uploads may contain a single well-framed shell, but they may also contain field backgrounds, hands, beach sand, rock, vegetation, labels, multiple specimens, poor focus, compression artefacts, very small shells, non-shell objects, or deliberate test uploads. This creates a substantial deployment gap between the visual distribution on which a classifier performs well and the distribution it actually receives in use. Such natural distribution shifts are known to reduce image-classifier performance, even when the shifted images remain semantically close to the original task [1, 2]. In ecological computer vision, similar problems have been demonstrated in camera-trap recognition, where classifiers can perform well in known environments but generalize poorly to new locations and backgrounds [3].
This problem is especially relevant for biodiversity image recognition. Large-scale citizen-science datasets such as iNaturalist were introduced precisely because natural-world recognition differs from conventional benchmark classification: species are long-tailed in frequency, visually similar taxa are common, image quality varies strongly, and photographs are taken across uncontrolled geographic, environmental, and photographic contexts [4]. Earlier work on bird-recognition applications similarly emphasized that real-world fine-grained datasets require careful treatment of annotation quality, class structure, and data-collection bias [5]. For shell identification, these issues are compounded by the fact that taxonomic expertise is unevenly distributed: many uploaded images come from occasional users rather than trained malacologists, while the downstream interpretation of the prediction may still be relevant to conchologists, collection curators, or taxonomic researchers.
A central failure mode of deep convolutional classifiers under such conditions is reliance on nuisance cues. Deep networks can exploit shortcuts: predictive signals that correlate with labels in the training distribution but are not causally tied to the biological object of interest [6]. Background and context are particularly important shortcut candidates. General image classifiers often benefit from object–context co-occurrence during training, but this reliance can reduce robustness when the object appears in an unusual context or when the context is misleading [7]. More directly, studies that separate foreground and background information show that image classifiers can be sensitive to background pixels, and that altering or removing backgrounds can materially change predictions rather than acting as a neutral transformation [8, 9]. In shell classification, the relevant biological signal should come primarily from shell morphology, yet raw user images may allow the classifier to attend to sand, rocks, hands, labels, lighting style, or photographic domain. [10] These cues may be useful within a restricted dataset but unreliable in a public deployment setting.
Object localization offers one possible way to reduce this nuisance variation before classification. Fine-grained visual-recognition research has repeatedly shown that localizing and magnifying informative regions can improve recognition when class differences are subtle. Recurrent attention models, for example, improve fine-grained classification by learning to “look closer” at discriminative regions [11], while mask-based approaches use object or part localization to select more informative descriptors for downstream recognition [12]. In applied biological settings, background removal has also been explored as a way to improve classification under in-situ conditions, for example in plant disease recognition where leaves photographed against soil, rocks, or human hands are segmented before classification [13]. These studies support the broader idea that object-centric preprocessing can improve downstream classification by increasing the relative contribution of the target organism and suppressing irrelevant context.
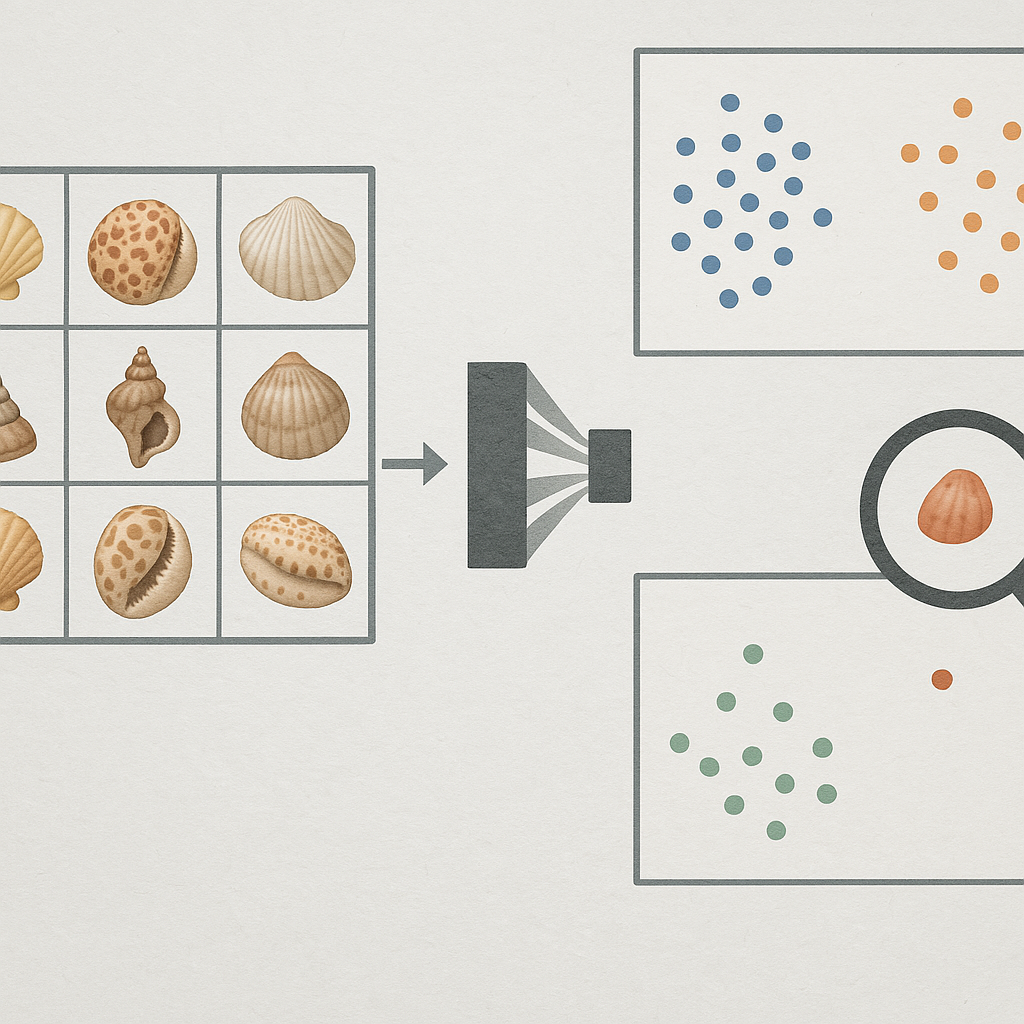
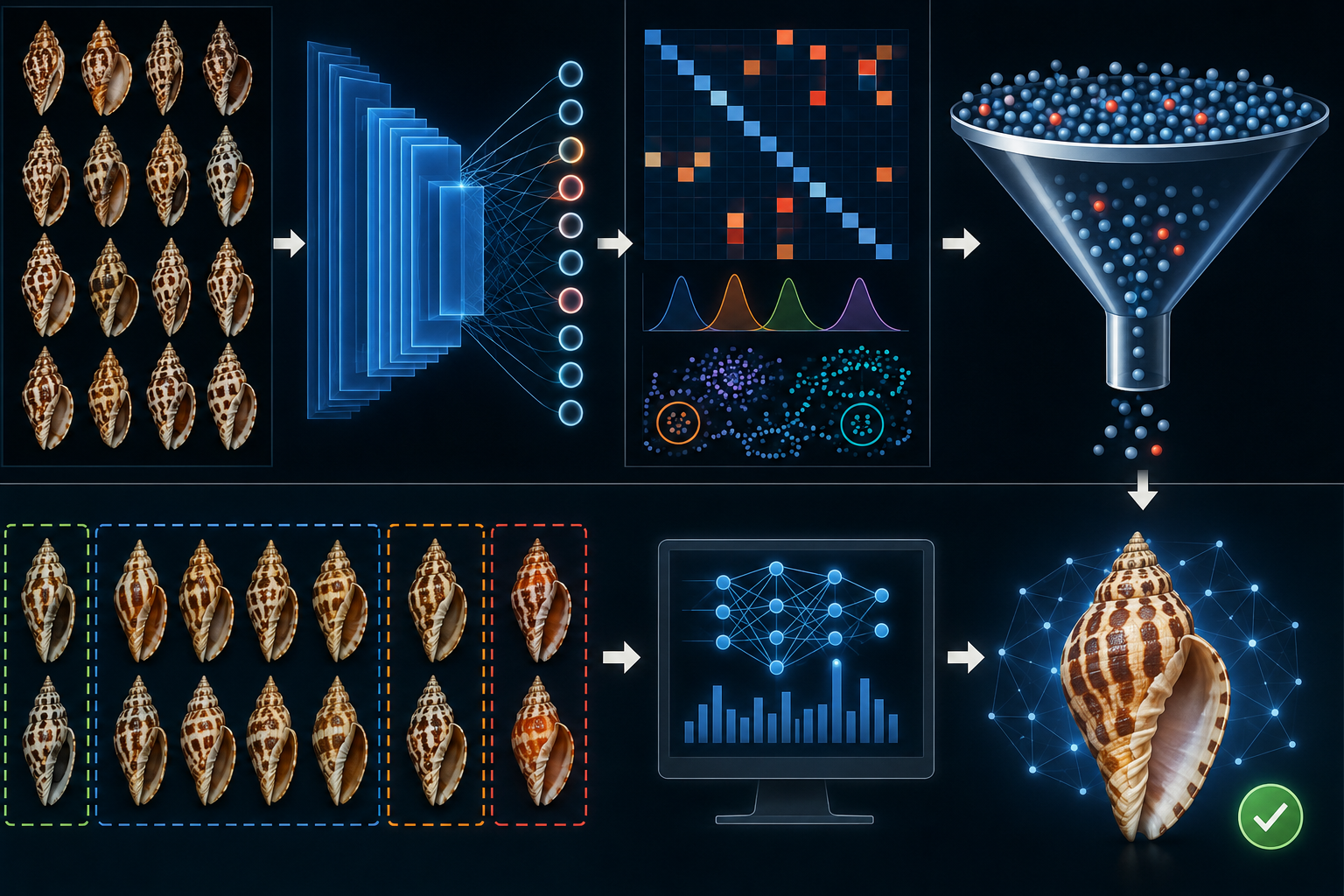
In the present study, we evaluate this principle in the IdentifyShell application by inserting a YOLO-based shell detection and segmentation stage before the existing taxonomic prediction pipeline. The standard prediction flow classifies the raw image by passing it to a domain router, a domain-aware family model, and then downstream genus and species models [14, 15]. The YOLO-assisted flow first detects shell presence, isolates one or more shell instances, crops and pads the selected instance, and replaces the background before passing the transformed image through the same downstream classification logic. This preprocessing step is therefore not treated merely as background removal. It combines shell detection, instance isolation, crop-based magnification, and background normalization. We refer to this broader intervention as object-centric preprocessing; when emphasizing its effect on the visual domain seen by the downstream model, we describe it as segmentation-assisted domain normalization.
The study differs from conventional curated benchmark evaluations in two important ways. First, the test set consists of real IdentifyShell user uploads from the first half of 2025, after duplicate uploads of the same image were removed but without any further quality- or content-based filtering. The dataset therefore includes valid shell images together with low-quality inputs, multi-object scenes and non-shell objects uploads. Second, the evaluation treats YOLO as part of the deployed recognition pipeline rather than as an isolated detector. The question is not only whether YOLO can detect shells, but whether its transformations improve or degrade family-level taxonomic classification under operational noise. This is important because localization errors can propagate into downstream taxonomic errors: a missed shell, an overly tight crop, or a wrong-object crop may remove the relevant morphology or force a non-shell object through a classifier that was designed for molluscan taxa.
The scientific gap addressed by this study lies at the intersection of biodiversity image classification, deployment robustness, and object-centric preprocessing. Prior work has established that image classifiers are vulnerable to natural distribution shift, that citizen-science biodiversity datasets are visually heterogeneous and taxonomically imbalanced, and that localization or masking can improve fine-grained recognition in benchmark settings. Less well studied is the performance of an independent detection/segmentation preprocessing layer inserted ahead of an existing hierarchical taxonomic classifier and evaluated on unfiltered production uploads. For conchological identification, this question is both technically and biologically relevant: a preprocessing step that suppresses background and isolates shell morphology may improve robustness on field and multi-object images, but it may also remove contextual or morphological information that is useful for already clean studio photographs.
This paper therefore asks whether YOLO-assisted object-centric preprocessing improves family-level shell classification in a real-world public identification pipeline. We evaluate overall family accuracy, top-3 family accuracy, domain-specific performance, prediction transitions between the original and YOLO-assisted flows, domain-router shifts, multi-object handling, confidence behaviour, and failure modes. By doing so, the study aims to clarify not only whether preprocessing improves classification, but also when it helps, when it hurts, and how it changes the visual domain seen by downstream taxonomic models.
Methods
Study design
This study used a paired within-image evaluation design. Each uploaded image was processed through two prediction flows: the standard IdentifyShell flow using the original image, and the YOLO-assisted flow using a shell-localized, cropped, and background-normalized representation of the same image. The downstream classification architecture was kept constant between the two flows: both representations were passed through the domain router and the corresponding domain-aware family classifier. Thus, the experiment tested the effect of changing the input representation before classification, rather than retraining or replacing the family-level classifier.
The primary endpoint was top-1 family-level classification accuracy. Secondary endpoints included top-3 family accuracy, image-level prediction transitions between the two flows, domain-router transitions, confidence changes, YOLO detection outcomes, multi-instance handling, and failure modes such as missed shells, wrong-object crops, very small shells, and crop clipping. Genus- and species-level models are part of the production IdentifyShell pipeline, but the present analysis focuses on family-level classification because family prediction is the first major taxonomic routing decision in the system.
Prediction-flow architecture
The evaluation compared two prediction flows applied to the same input image. The first flow was the standard prediction pipeline, in which the raw image was passed directly to the domain router. The router assigned the image to one of the available image-domain categories, after which the corresponding domain-aware family model was used for family-level classification. The family-level result then determined which downstream genus- and species-level models would be relevant for further taxonomic classification.
The second flow introduced a YOLO-based preprocessing step before classification. In this YOLO-assisted flow, the raw image was first processed by a shell-detection and segmentation model. When a shell was detected, the selected instance was cropped, padded, and transformed into a standardized image with background replacement. This transformed image was then passed through the same downstream logic as the standard flow: domain routing, domain-aware family classification, and subsequent genus- and species-level classification.
This design allowed the original and YOLO-normalized representations of the same specimen to be compared directly. The standard flow tested classification performance on the original full image, including its natural background, framing, and possible clutter. The YOLO-assisted flow tested whether object localization, effective shell magnification, multi-object isolation, and background normalization improved classification. Because the domain router was applied separately to the original image and to the YOLO-transformed image, the two flows could also produce different domain assignments. This is important for interpreting the results: changes in classification performance may arise not only from the cropped shell image itself, but also from changes in the domain-aware model selected by the router.
The two-flow setup was therefore used both as an accuracy comparison and as a reliability analysis. Cases where the original and YOLO-assisted predictions agreed were treated as high-consistency cases. Cases where YOLO corrected an initially wrong prediction were used to quantify the benefit of preprocessing. Conversely, cases where the original prediction was correct but the YOLO-assisted prediction was wrong were used to identify risks introduced by cropping, segmentation, background replacement, or loss of contextual information.
Evaluation dataset
The evaluation dataset consisted of images uploaded by users of the IdentifyShell application for taxonomic classification. To obtain a temporally defined and reproducible sample of real-world user submissions, only images uploaded during the first half of 2025 were included. When the same image was uploaded multiple times, duplicate submissions were removed and only a single instance was retained. No additional quality-based or content-based filtering was applied. Consequently, the dataset includes the full range of user-submitted material observed in operational use, including well-framed shell photographs, cluttered or multi-object images, poor-quality images, non-shell objects, and images apparently uploaded as jokes or invalid test cases. This design was intended to evaluate the classification pipeline under realistic deployment conditions rather than under a curated benchmark setting.
Image-domain categories
Images were stratified by the domain assigned by the domain router. The term domain refers to the visual acquisition context of the image, not to a taxonomic or ecological category. Three main domains were used. Studio images are controlled specimen photographs, typically showing a cleaned and centered shell under stable lighting against a uniform or non-distracting background. Home images are informal user photographs taken under non-professional but relatively controlled conditions, for example a shell photographed on a table, paper, hand, or other domestic background; these images are less standardized than studio photographs but usually still show the shell as the main subject. Field images are uncontrolled in-situ or outdoor photographs in which the shell is embedded in a natural or visually complex context, such as sand, rocks, algae, debris, other organisms, variable lighting, partial occlusion, or non-standard pose. This domain stratification was used to evaluate whether YOLO-assisted preprocessing had different effects on already clean images compared with visually cluttered or environmentally variable user uploads [10].
Manual review and correctness labelling
The evaluation used a manual review procedure to assign correctness labels to the outputs of the detection and classification pipeline. All image reviews were performed by the author. The aim of the review was not to create a complete taxonomic benchmark with a manually assigned family label for every uploaded image. Instead, the review assigned binary correctness labels needed to compare the two prediction flows: whether a shell was present, whether YOLO localized the relevant shell correctly, and whether the family-level prediction returned by each flow was correct or incorrect.
For YOLO evaluation, each image was reviewed for shell presence and localization quality. A YOLO localization was reviewed as correct when the selected bounding box or mask enclosed the shell specimen intended for classification. It was reviewed as wrong when the selected crop corresponded to a non-shell object, an irrelevant background structure, or another artefact rather than the shell. When YOLO produced no crop, the case was classified as a true negative if no shell was visible in the image, and as a missed-shell failure if a shell was visible but no YOLO detection was produced.
For family-level classification, the top-1 family prediction from the standard flow and the top-1 family prediction from the YOLO-assisted flow were reviewed separately as correct or incorrect. The review therefore recorded whether the predicted family was compatible with the visible shell, rather than assigning a new complete taxonomic label to every image. Cases in which family-level correctness could not be judged with sufficient confidence were treated as uncertain and excluded from analyses requiring a binary correct/wrong decision.
Non-shell uploads were retained in the dataset because they represent realistic operational input to a public identification system. These images were used to evaluate shell-presence detection and no-object handling. They were not assigned a taxonomic family. When no shell was present and YOLO produced no crop, the YOLO outcome was treated as a true negative for detection. If a non-shell object was detected and passed to the classifier, this was treated as a wrong-object detection and a potential pipeline failure, because the downstream taxonomic classifier was forced to classify an invalid input.
The manual review was used to define image-level transitions between the two prediction flows. A case was labelled as “YOLO helped” when the original-image prediction was incorrect and the YOLO-assisted prediction was correct. A case was labelled as “YOLO hurt” when the original-image prediction was correct and the YOLO-assisted prediction was incorrect. Cases were labelled as “unchanged correct” when both flows produced a correct family prediction, and as “unchanged wrong” when neither flow produced the correct family prediction. These transition labels were used to quantify the net effect of YOLO-assisted preprocessing and to identify failure modes introduced by detection, cropping, segmentation, or background replacement.
Where applicable, the review of YOLO localization quality was performed independently of the downstream family-classification outcome. Thus, a crop could be reviewed as a correct shell localization even if the subsequent family prediction was wrong, and conversely a correct family prediction did not by itself imply that the YOLO localization was accepted as correct. This separation allowed detection errors and classification errors to be analysed as distinct components of the combined pipeline.
YOLO-assisted preprocessing algorithm
The YOLO-assisted prediction flow used the trained shell instance-segmentation model as a preprocessing step before taxonomic classification. For each input image, YOLO was first applied to detect candidate shell instances and, when possible, to generate a segmentation mask for each detected instance. The aim of this step was to convert the original user-uploaded image into a shell-centred representation with reduced background information before applying the same downstream classification pipeline used for the original image.
When one or more shell instances were detected, a single instance was selected for downstream classification. In multi-instance images, the selected instance was the detection with the highest YOLO confidence score. This rule was used as a deterministic instance-selection procedure and ensured that only one transformed image was passed to the downstream domain router and family classifier for the paired comparison. The rule does not imply that the selected object was always the biologically most relevant specimen in the image; this was evaluated separately during manual review.
The selected YOLO bounding box was used to define the crop region. To avoid overly tight crops and to retain a limited amount of surrounding morphology and context, the bounding box was expanded using a fixed padding factor of 0.14. The padded crop was then clipped to the original image boundaries whenever the expanded crop extended beyond the image dimensions. This clipping step ensured that all transformed images could be generated from valid pixel coordinates, but it also created a measurable crop-geometry variable because shells near the image border could lose part of the intended padding.
| Setting | Value | Interpretation |
|---|---|---|
| Crop padding | 0.14 | Additional margin retained around the detected shell crop. |
| Background replacement | black | Background used after YOLO-based foreground isolation. |
| Detected rows with confidence values | 851 | Rows where at least one YOLO object was detected. |
| Mean YOLO detection confidence | 85.8% | Average confidence across detected rows. |
The segmentation mask associated with the selected instance was used to define foreground and background pixels within the crop. Pixels outside the selected shell mask were replaced by a uniform black background. This produced a foreground-isolated image in which the shell occupied a larger proportion of the classifier input and non-shell visual context was suppressed. The transformed crop was then resized to the input dimensions required by the downstream classification models.
If YOLO produced no detection, no YOLO-transformed crop was available for that image. These cases were retained in the evaluation and reviewed separately as either true negatives, when no shell was visible in the image, or missed-shell failures, when a shell was visible but YOLO failed to detect it. No-detection cases were therefore analysed as part of the combined preprocessing-classification pipeline rather than being silently removed from the dataset.
The YOLO-transformed image was passed through the same downstream logic as the original image: domain routing followed by the corresponding domain-aware family classifier. The domain router was applied independently to the original and YOLO-transformed images. Consequently, YOLO preprocessing could affect the final family prediction in two ways: by changing the visual content presented to the family classifier, and by changing the domain assignment that determined which domain-aware family model was used.
Handling of no-detection cases
No-detection cases were retained in the evaluation because they represent an important operational outcome of the YOLO-assisted prediction flow. A no-detection case occurred when the YOLO model did not return a shell crop for the uploaded image. In such cases, the YOLO-assisted branch stopped after the detection stage: no transformed image was generated, and no downstream domain-router or family-classification prediction was produced for the YOLO-assisted flow.
No-detection outcomes were reviewed independently of the standard prediction flow. Each no-detection case was assigned a detection-level review tag. If no shell was visible in the image, the no-detection outcome was treated as a true negative for the YOLO detector. If a shell was visible but YOLO failed to detect it, the outcome was treated as a missed-shell failure. These labels describe the performance of the detection step only and do not depend on whether the standard classification flow produced a correct or incorrect family prediction.
The standard prediction flow was still evaluated for the same images. Because the standard flow does not depend on YOLO detection, the original image was passed directly to the domain router and family classifier, and its family-level prediction was reviewed as correct or incorrect in the same way as for all other images. Thus, an image with no YOLO detection could still have a correct or incorrect standard-flow family prediction.
For the YOLO-assisted classification analysis, no-detection cases were not replaced by a fallback prediction from the original image. They were retained as “no YOLO crop available” cases. Consequently, they did not contribute a correct family prediction to the YOLO-assisted branch, because that branch produced no family classification. This design evaluates the pure YOLO-assisted flow as a preprocessing-dependent pipeline, rather than a production fallback strategy in which the original-image classifier would automatically be used when YOLO fails.
This distinction is important for interpretation. True-negative no-shell cases indicate useful shell-presence filtering by YOLO, whereas missed-shell cases represent detection failures that prevent downstream classification. Both outcomes are detection-level events, but only missed-shell failures are biologically relevant failures for shell-image classification. In a future production implementation, no-detection cases could trigger fallback to the standard original-image flow or manual review, but such fallback behaviour was not included in the present paired-flow experiment.
YOLO shell-detection and segmentation model
The object-localization component was implemented as a single-class YOLO instance-segmentation model. The model was trained to detect and segment shell objects only, using the class definition 0 = shell. Training labels were retrieved and linked to image candidates. Only reviewed records marked as usable for training were included. Positive training examples consisted of images labelled as shell or multi_shell with at least one annotated shell instance, whereas hard-negative examples consisted of images labelled as no_shell.
The training export contained 698 usable images, including 598 positive shell images and 100 hard-negative no-shell images. Images were exported from two source roots: images from a shell auction and IdentifyShell user-uploaded images. Polygon annotations were converted to YOLO segmentation-label format, with normalized x–y coordinates. For no-shell hard-negative images, an empty label file was written, so that the model could learn background and non-shell cases without a positive object annotation.
The dataset was split randomly into training, validation, and test partitions using a fixed seed. The split proportions were 70% training, 20% validation, and 10% test, corresponding to 488 training images, 139 validation images, and 71 test images. The model was initialized from yolov8n-seg.pt and trained for 30 epochs with an image size of 640 pixels using the Ultralytics YOLO framework. Training was performed with Ultralytics 8.4.41, Python 3.10.12, PyTorch 2.11.0 with CUDA support, and an NVIDIA GeForce RTX 3080 GPU.
After training, the best model checkpoint was validated on the exported validation set. The validation set contained 139 images and 141 shell instances, including 18 background images. The trained model achieved high validation performance for both bounding boxes and masks, with box precision 0.930, recall 0.979, mAP50 0.988, and mAP50–95 0.921. Mask performance was similar, with mask precision 0.930, recall 0.979, mAP50 0.988, and mAP50–95 0.915. These validation metrics were used to confirm that the YOLO model was suitable as a shell-localization component before evaluating its downstream effect on family-level classification.
Evaluation endpoints and metrics
Family-level accuracy was calculated as the proportion of reviewed images for which the predicted top-1 family matched the verified family label. Top-3 family accuracy was calculated as the proportion of images for which the verified family appeared among the three highest-scoring family predictions.
Domain-stratified analysis
Because the domain router was applied separately to the original and YOLO-transformed image, preprocessing could change both the visual input and the downstream family model selected by the router.
Statistical analysis
Because original and YOLO-assisted predictions were obtained for the same images, top-1 accuracy differences were treated as paired outcomes. The primary paired comparison was summarized by the number of discordant cases in which YOLO corrected an originally wrong prediction and the number of cases in which YOLO degraded an originally correct prediction. Statistical significance can be assessed using McNemar’s test, and confidence intervals for accuracy differences can be estimated by non-parametric bootstrap resampling over images.
Results
YOLO Detection and Segmentation Outcomes
YOLO produced a correct bounding-box or correct no-object outcome in 856 of 1,004 images, corresponding to 85.3% of the dataset. YOLO was reviewed as wrong in 148 images, corresponding to 14.7%.
YOLO detected one shell instance in 726 images and multiple shell instances in 125 images. No object was detected in 153 images. These no-detection cases are not all failures: 83 were true negatives where no shell was present, whereas 70 were missed-shell failures where a shell was present but YOLO failed to detect it.
| Outcome | Count | Percentage | Definition |
|---|---|---|---|
| One shell detected | 726 | 72.3% | Instances = 1 |
| Multiple shells detected | 125 | 12.5% | Instances > 1 |
| No shell detected | 153 | 15.2% | Instances = 0 or null |
| Wrong object detected | 78 | 7.8% | YoloReviewTag = wrong and Instances > 0 |
Wrong-object detections occurred in 78 images. These are important because they represent a different failure mode from no detection: the pipeline detected and cropped an object, but the cropped object was not a shell.
| No-detection category | Count | Share of no-detection cases | Interpretation |
|---|---|---|---|
| True negative | 83 | 54.2% | No shell was present and YOLO correctly detected no object. |
| Missed shell | 70 | 45.8% | A shell was present, but YOLO failed to detect it. |
| Total no-detection cases | 153 | 100.0% | Total rows where no YOLO crop was available. |
YOLO confidence and detection correctness
YOLO detection confidence was positively associated with review correctness. The correct rate increased from 75.7% for detections below 0.50 confidence to 94.1% for detections with confidence of at least 0.90. This shows that YOLO confidence is informative, although not sufficient as a standalone acceptance criterion: 30 detections in the ≥0.90 confidence bucket were still reviewed as wrong.
| Confidence bucket | Total detections | YOLO correct | YOLO wrong | YOLO correct rate |
|---|---|---|---|---|
| <0.50 | 37 | 28 | 9 | 75.7% |
| 0.50–0.70 | 65 | 51 | 14 | 78.5% |
| 0.70–0.90 | 244 | 219 | 25 | 89.8% |
| ≥0.90 | 505 | 475 | 30 | 94.1% |
Detection correctness was similar for one-shell and multi-shell detections. One-shell images had a YOLO correct rate of 90.6%, while multi-shell images had a correct rate of 92.0%. This indicates that the presence of multiple detected objects did not by itself make YOLO detection substantially less reliable.
| Detected object mode | Total images | YOLO correct | YOLO wrong | YOLO correct rate |
|---|---|---|---|---|
| One shell | 726 | 658 | 68 | 90.6% |
| Multiple shells | 125 | 115 | 10 | 92.0% |
| No shell detected | 153 | 83 | 70 | 54.2% |
Overall classification performance
YOLO-assisted preprocessing improved family-level classification accuracy from 33.4% on the original full images to 44.1% after YOLO crop and background normalization. This corresponds to an absolute gain of 10.8 percentage points. Top-3 family accuracy also improved, from 52.3% to 58.0%, corresponding to an absolute gain of 5.7 percentage points.
These results show that the benefit of YOLO preprocessing is not limited to filtering invalid images. The cropped and background-normalized view also improves the classifier’s ability to place the image in the correct family.
| Input condition | Family accuracy | Top-3 family accuracy |
|---|---|---|
| Original image baseline | 33.4% | 52.3% |
| YOLO crop + background normalization | 44.1% | 58.0% |
| Absolute gain | +10.8 pp | +5.7 pp |
Correctness transitions before and after YOLO preprocessing
The image-level transition analysis shows where YOLO changed the classification outcome. YOLO helped in 181 images, meaning that the original prediction was wrong but the YOLO-preprocessed prediction was correct. YOLO hurt in 52 images, meaning that the original prediction was correct but the YOLO-preprocessed prediction was wrong. A further 262 images were correct in both flows, while 356 images were wrong in both flows. In 153 images, no YOLO crop was available because no object was detected.
Thus, among rows where a YOLO crop was available, the net effect was strongly positive: 181 helped cases versus 52 hurt cases.
| Impact of YOLO preprocessing | Image count | Share of dataset | Description |
|---|---|---|---|
| YOLO helped | 181 | 18.0% | Original prediction wrong, YOLO prediction correct. |
| YOLO hurt | 52 | 5.2% | Original prediction correct, YOLO prediction wrong. |
| Unchanged correct | 262 | 26.1% | Correct in both flows. |
| Unchanged wrong | 356 | 35.5% | Wrong in both flows. |
| No YOLO crop available | 153 | 15.2% | No crop evaluated because no object was detected. |
| Total | 1,004 | 100.0% | Total synced records with classification reviews. |
Domain-specific classification performance
The effect of YOLO preprocessing differed strongly by image domain. Studio images had the highest baseline accuracy, at 84.8%, and decreased slightly to 78.3% after YOLO preprocessing. This suggests that clean studio images may already be close to the classifier’s preferred input distribution, and that additional cropping or background replacement can remove useful context or introduce unnecessary transformation.
User/home images changed only marginally, from 61.3% to 61.8%. Field images showed a much larger improvement, increasing from 22.7% to 37.1%, an absolute gain of 14.4 percentage points. This indicates that YOLO preprocessing is most beneficial for images with field-like background clutter, uncontrolled framing, or strong non-shell visual context.
The multi-object subset also showed a strong gain. In 124 valid multi-object cases, accuracy increased from 33.1% to 51.6%, an absolute improvement of 18.5 percentage points. This supports the interpretation that YOLO is useful not only as a background-normalization tool, but also as a mechanism for isolating individual shell instances in visually complex images.
| Image domain / condition | Total images | Original accuracy | YOLO accuracy | Absolute gain |
|---|---|---|---|---|
| Studio | 46 | 84.8% | 78.3% | −6.5 pp |
| User/home | 204 | 61.3% | 61.8% | +0.5 pp |
| Field | 750 | 22.7% | 37.1% | +14.4 pp |
| Multi-object | 124 | 33.1% | 51.6% | +18.5 pp |
Domain-router transitions after YOLO preprocessing
YOLO preprocessing substantially changed the apparent domain assigned by the router. The most common transition was from field to home, occurring in 383 images, or 38.3% of the analyzed dataset. A further 72 images shifted from field to studio. Together, these transitions indicate that YOLO cropping and black-background normalization removed many field-background cues and made the classifier input appear more similar to home or studio imagery.
The domain-transition results support the interpretation that YOLO acts as a domain-normalization layer. It does not merely crop the shell; it changes the visual context on which the domain router operates.
| Original domain → YOLO domain | Count | Share of dataset | Interpretation |
|---|---|---|---|
| field → home | 383 | 38.3% | Field background cues were removed. |
| field → studio | 72 | 7.2% | Crop and background replacement made the image more studio-like. |
| field → field | 161 | 16.1% | Field-like visual character remained after preprocessing. |
| studio → studio | 37 | 3.7% | Studio image remained stable. |
| studio → home/field | 8 | 0.8% | YOLO preprocessing shifted a clean image away from studio. |
| home → home | 134 | 13.4% | Home-domain image remained stable. |
| home → studio | 50 | 5.0% | Background normalization increased studio similarity. |
| no YOLO detection | 153 | 15.3% | No crop was extracted. |
| other transitions | 2 | 0.2% | Other domain shifts. |
Classification gain was largest when original field images were shifted into home-like or studio-like representations. The field → home transition alone accounted for a net gain of 93 correct classifications. Field → studio added a further 13, and field → field added 20. In contrast, studio → studio and home → studio transitions showed small negative effects.
| Domain transition | N | Original correct | YOLO correct | Original accuracy | YOLO accuracy | Net gain |
|---|---|---|---|---|---|---|
| field → home | 383 | 104 | 197 | 27.2% | 51.4% | +93 |
| field → studio | 72 | 21 | 34 | 29.2% | 47.2% | +13 |
| field → field | 161 | 27 | 47 | 16.8% | 29.2% | +20 |
| studio → studio | 37 | 33 | 31 | 89.2% | 83.8% | −2 |
| studio → home/field | 8 | 6 | 5 | 75.0% | 62.5% | −1 |
| home → home | 134 | 82 | 86 | 61.2% | 64.2% | +4 |
| home → studio | 50 | 40 | 39 | 80.0% | 78.0% | −1 |
| no YOLO detection | 153 | 21 | 0 | 13.7% | 0.0% | −21 |
| other transitions | 2 | 0 | 1 | 0.0% | 50.0% | +1 |
Agreement between original and YOLO-normalized predictions
Agreement between the original and YOLO-normalized prediction flows was a strong reliability signal. In 338 images, corresponding to 33.7% of the dataset, the original and YOLO top-1 predictions agreed. This agreement subset had 77.5% verified accuracy, substantially higher than the overall accuracy of either individual flow.
In 181 images, the YOLO prediction was correct while the original prediction was different and incorrect. This is the clearest evidence that YOLO preprocessing improved classification. Conversely, in 73 images, the original prediction was correct while the YOLO prediction was different. This group includes cases where segmentation or cropping may have removed useful context or diagnostic information. The remaining 412 images were unresolved: neither flow produced the verified correct prediction.
| Prediction relationship | Image count | Share of dataset | Sub-segment accuracy | Interpretation |
|---|---|---|---|---|
| Original and YOLO agree | 338 | 33.7% | 77.5% | High-trust subset. |
| Original correct, YOLO different | 73 | 7.3% | 100.0% original | YOLO introduced risk or removed useful information. |
| YOLO correct, original different | 181 | 18.0% | 100.0% YOLO | YOLO preprocessing helped. |
| Neither flow correct / unresolved | 412 | 41.0% | 0.0% | Candidate for abstention, fallback, or review. |
Auto-acceptance rules based on agreement and confidence
The agreement analysis can be converted into practical decision rules. Accepting all cases where the original and YOLO top-1 predictions agree would cover 338 images, or 33.7% of the dataset, with 77.5% verified accuracy. Stricter rules substantially increased accuracy at the cost of lower coverage.
The strongest rule was agreement combined with both original and YOLO scores ≥0.70. This covered 114 images, or 11.4% of the dataset, and achieved 99.1% verified accuracy. Agreement plus YOLO score ≥0.70 achieved 98.7% accuracy at 15.6% coverage. Agreement plus YOLO score ≥0.90 achieved 99.0% accuracy at 9.9% coverage.
These results indicate that a dual-view confidence gate can isolate a small but highly reliable subset of images for automatic acceptance, while leaving the remaining images for fallback handling or expert review.
| Auto-accept rule | Coverage | Verified accuracy |
|---|---|---|
| Original and YOLO top-1 agree | 338 (33.7%) | 262/338 (77.5%) |
| Agree + YOLO score ≥0.70 | 157 (15.6%) | 155/157 (98.7%) |
| Agree + YOLO score ≥0.90 | 99 (9.9%) | 98/99 (99.0%) |
| Agree + original score ≥0.70 and YOLO score ≥0.70 | 114 (11.4%) | 113/114 (99.1%) |
| Agree + router domains agree | 162 (16.1%) | 121/162 (74.7%) |
| Agree + no API errors | 258 (25.7%) | 219/258 (84.9%) |
High-confidence wrong predictions
High-confidence wrong predictions were relatively uncommon in the YOLO flow. The standard prediction flow produced 85 wrong predictions with score ≥0.70 and 15 wrong predictions with score ≥0.90. The YOLO prediction flow produced 10 wrong predictions with score ≥0.70 and only 1 wrong prediction with score ≥0.90.
| Flow | Wrong predictions with score ≥0.70 | Wrong predictions with score ≥0.90 |
|---|---|---|
| Standard predict | 85 | 15 |
| YOLO predict | 10 | 1 |
The most important risk category is agreement between the original and YOLO flows when both are wrong. This occurred in 76 images. These cases are important because simple agreement alone would not identify them as unreliable; confidence thresholds or additional quality-control criteria are needed.
| Case | Count |
|---|---|
| Original and YOLO agree, but both are wrong | 76 |
| YOLO top-1 score ≥0.90 and YOLO prediction is wrong | 1 |
| Original top-1 score ≥0.90 and original prediction is wrong | 3 |
Confidence shift after YOLO preprocessing
YOLO preprocessing increased average top-1 classification confidence. The mean top-1 score in the standard prediction flow was 38.7%, compared with 47.6% in the YOLO-assisted flow. The mean row-wise score delta after YOLO preprocessing was +7.6%.
The score shift differed by outcome category. In helped cases, the average score delta was +22.1%, indicating that YOLO often made the correct prediction substantially more confident. In hurt cases, the score delta was −10.1%, suggesting that the YOLO-preprocessed image often reduced confidence when it degraded the classification outcome. Stable cases showed a smaller positive mean score delta of +4.8%.
| Statistic | Value | Interpretation |
|---|---|---|
Mean Top-1 Score |
38.7% | Baseline top-1 confidence. |
Mean Yolo Top-1 Score |
47.6% | YOLO-flow top-1 confidence. |
Mean row-wise Yolo Vs Predict Score Delta |
+7.6% | Average confidence gain after YOLO. |
| Score delta in helped cases | +22.1% | YOLO became more confident when it corrected the prediction. |
| Score delta in hurt cases | −10.1% | YOLO confidence decreased in cases where it hurt. |
| Score delta in stable cases | +4.8% | Small confidence gain when outcome was stable. |
| High-confidence YOLO wrong predictions ≥0.90 | 1 | Low but non-zero user-trust risk. |
Occupancy and crop magnification
YOLO preprocessing increased the relative size of the shell region in the classifier input. Before cropping, the average bounding box occupied 28.2% of the original image area, while the average mask occupied 19.1%. After clipped padded cropping, the average bounding-box occupancy increased to 64.2%, and the average mask occupancy increased to 44.2%.
This supports one of the main mechanisms behind the accuracy gain: YOLO does not only remove background; it also increases the effective visual scale of the shell before classification.
| Metric | Average | Meaning |
|---|---|---|
| Bbox before crop | 28.2% | Detection rectangle divided by original image area. |
| Mask before crop | 19.1% | Detected shell mask divided by original image area. |
| Bbox after clipped padded crop estimate | 64.2% | Detection rectangle divided by padded crop area, clamped to image bounds. |
| Mask after clipped padded crop estimate | 44.2% | Detected shell mask divided by padded crop area, clamped to image bounds. |
The group-specific magnification analysis further supports this mechanism. YOLO-helped cases had the smallest initial mean bbox occupancy, at 18.2%, and were magnified to 62.1% after cropping. The magnification factor reported in Table 17 is the mean of the per-image magnification ratios, not the ratio of the displayed group means.
| Group | N | Mean bbox occupancy before | Mean bbox occupancy after crop | Mean per-image magnification factor | Interpretation |
|---|---|---|---|---|---|
| YOLO helped | 181 | 18.2% | 62.1% | 7.57× | YOLO strongly magnified small shell regions and improved classification. |
| YOLO hurt | 52 | 34.5% | 65.4% | 4.54× | YOLO enlarged the crop but sometimes removed useful context or morphology. |
| Both correct | 262 | 37.0% | 65.3% | 2.90× | Shells were already relatively large; preprocessing was less critical. |
| Both wrong | 356 | 25.9% | 64.2% | 6.77× | Magnification occurred, but classification still failed. |
Classification impact by initial shell size
Initial shell size strongly affected classification performance. Very small shells, defined as bbox occupancy below 5% of the original image area, had very poor baseline accuracy: only 7.4% on the original images. YOLO preprocessing increased accuracy in this group to 40.0%, an absolute gain of 32.6 percentage points. However, this group remained the most difficult overall, indicating that scaling up a very small object cannot fully recover fine morphological detail lost in the original image.
Medium-sized shells, with bbox occupancy between 5% and 20%, showed the largest absolute net gain in correct classifications: +67 cases. Large shells, with bbox occupancy ≥20%, also improved, but the gain was smaller because the shell was already visually prominent in the original image.
| Bbox occupancy group | N | Original accuracy | YOLO accuracy | YOLO helped | YOLO hurt | Net gain |
|---|---|---|---|---|---|---|
| <5% | 95 | 7.4% | 40.0% | 34 | 3 | +31 |
| 5–20% | 292 | 27.7% | 50.7% | 84 | 17 | +67 |
| ≥20% | 464 | 48.7% | 55.4% | 63 | 32 | +31 |
Crop clipping and boundary risk
Crop geometry also influenced performance. When the padded crop was not clipped by the image boundary, YOLO accuracy was 51.2%. Minor clipping had the highest YOLO accuracy, at 55.9%, suggesting that small losses of padding do not necessarily damage the crop. However, substantial clipping reduced YOLO accuracy to 47.2% and increased the failure rate to 52.8%.
This indicates that severe crop clipping is a measurable risk factor. It likely occurs when the detected shell lies too close to the image boundary, causing part of the intended padded crop to fall outside the original image. Such cases may benefit from fallback to the original full image or from a less aggressive crop policy.
| Crop clipping group | N | Average clipping loss | YOLO accuracy | Failure rate |
|---|---|---|---|---|
| No clipping | 533 | 0.0% | 51.2% | 48.8% |
| Minor clipping | 229 | 7.2% | 55.9% | 44.1% |
| Substantial clipping | 89 | 21.7% | 47.2% | 52.8% |
Multi-instance image analysis
YOLO detected multiple shell instances in 125 rows. For the valid multi-object performance subset, the classification gain was substantial: accuracy increased from 33.1% to 51.6%, an absolute improvement of 18.5 percentage points. This confirms that multi-object images are an important use case for YOLO preprocessing.
In the shell-count analysis, one-shell images improved from 37.6% to 52.2%, and multi-shell images improved from 32.8% to 51.2%. Thus, the gain was not limited to single-object inputs. The multi-shell group showed a net gain of 23 correct classifications, indicating that YOLO instance selection can reduce confusion caused by mixed or cluttered visual input.
| Segment | N | Original accuracy | YOLO accuracy | YOLO helped | YOLO hurt | Net gain |
|---|---|---|---|---|---|---|
| One-shell | 726 | 37.6% | 52.2% | 152 | 46 | +106 |
| Multi-shell | 125 | 32.8% | 51.2% | 29 | 6 | +23 |
The multi-shell cases contained an average of 2.34 detected shell instances, with a maximum of 7. Across all detected images, the mean number of proposed instances was 1.20. In multi-shell cases, the mean maximum instance confidence was 88.0%, the mean average instance confidence was 79.6%, and the mean minimum instance confidence was 71.3%.
The selected instance was the highest-confidence YOLO detection in all 125 multi-shell cases. This confirms that the implemented instance-selection rule consistently chooses the highest-confidence candidate. It does not necessarily prove that the selected instance is always the biologically most relevant shell, but it does confirm internal consistency of the selection procedure.
| Metric | Value | Interpretation |
|---|---|---|
| Mean instances across all detected images | 1.20 | Most detected images contain a single proposed shell. |
| Mean instances in multi-shell cases | 2.34 | Multi-shell images usually contain two to three candidate shells. |
| Maximum number of instances | 7 | Highest observed number of proposed shell instances. |
| Mean maximum instance confidence | 88.0% | Confidence of the best candidate in multi-shell images. |
| Mean average instance confidence | 79.6% | Average confidence across proposed shells. |
| Mean minimum instance confidence | 71.3% | Confidence of the weakest proposed shell candidate. |
| Mean selected instance confidence | 88.0% | Confidence of the crop passed to the classifier. |
| Selected instance was highest-confidence object | 125/125 | The selection rule consistently picked the highest-confidence candidate. |
YOLO helped/hurt analysis by detection quality and confidence
Classification improvement was strongly associated with YOLO detection quality. When the YOLO bounding box was reviewed as correct, YOLO helped in 181 cases and hurt in 50, giving a net effect of +131. When the bounding box was reviewed as wrong, YOLO never helped and hurt in 2 cases. This indicates that most classification gains depend on correct shell localization, while wrong-object crops are mainly a source of risk.
| YOLO bbox review | N | YOLO helped | YOLO hurt | Net effect | Interpretation |
|---|---|---|---|---|---|
| Correct bbox | 773 | 181 | 50 | +131 | Correct localization usually benefits classification. |
| Wrong bbox | 78 | 0 | 2 | −2 | Wrong-object crops do not help and can degrade output. |
| No detection | 153 | 0 | 0 | −21 | No crop available; original flow may still classify some images. |
The classification benefit also increased with YOLO confidence. The ≥0.90 confidence bucket produced the largest net gain, with 115 helped cases, 34 hurt cases, and a net gain of +81. The 0.70–0.90 bucket also showed a strong positive effect, with a net gain of +43. Lower-confidence detections contributed much smaller gains.
| YOLO confidence bucket | N | YOLO helped | YOLO hurt | Net gain | YOLO classification accuracy |
|---|---|---|---|---|---|
| <0.50 | 37 | 5 | 1 | +4 | 37.8% |
| 0.50–0.70 | 65 | 7 | 6 | +1 | 30.8% |
| 0.70–0.90 | 244 | 54 | 11 | +43 | 42.6% |
| ≥0.90 | 505 | 115 | 34 | +81 | 60.4% |
Pipeline failure modes
Three main failure modes were identified in the combined YOLO-classifier pipeline. First, YOLO failed to detect a shell in 70 images, corresponding to 7.0% of the dataset. These are missed-shell failures, not all no-detection cases. Second, wrong-object detections occurred in 78 images, corresponding to 7.8%. These cases are potentially more problematic than no detections because a non-target crop can still be passed to the classifier and produce a false prediction. Third, 95 images contained very small shells, defined as bbox occupancy below 5% of the original image area.
| Failure mode | Image count | Share of dataset | Example consequence | Database context |
|---|---|---|---|---|
| Shell not detected | 70 | 7.0% | No YOLO crop available for shell classification. | A shell was present, but YOLO failed to detect a shell bounding box. |
| Wrong object detected | 78 | 7.8% | False classification risk. | YOLO detected and cropped a distractor or background artifact. |
| Very small shell | 95 | 9.5% | Insufficient diagnostic detail. | Bounding box occupied <5% of the original image area. |
The small-shell category had the highest classification failure rate, at 60.0%. This confirms that object localization alone does not fully solve the recognition problem when the shell occupies too few pixels in the original image. Cropping can magnify the target, but it cannot restore fine detail that was never captured at sufficient resolution.
| Shell size / crop ratio | Total crops | Classification failures | Error rate | Interpretation |
|---|---|---|---|---|
| Very small shell (<5%) | 95 | 57 | 60.0% | Highest failure rate; scale-up pixelation remains limiting. |
| Medium shell (5–20%) | 292 | 144 | 49.3% | Intermediate failure rate. |
| Large shell (≥20%) | 464 | 207 | 44.6% | Lowest failure rate among crop-size groups. |
Summary of results
The results show that YOLO-assisted preprocessing substantially improves family-level classification on heterogeneous shell images. Overall family accuracy increased from 33.4% to 44.1%, and top-3 family accuracy increased from 52.3% to 58.0%. The improvement was not uniform across all image types. Clean studio images showed a small decrease, user/home images were nearly unchanged, while field and multi-object images improved strongly.
The main mechanism appears to be a combination of shell localization, effective magnification, background normalization, and domain-router shift. YOLO preprocessing often moved images originally classified as field-domain into home-like or studio-like representations, and these transitions accounted for much of the observed gain. The field → home transition alone produced a net gain of 93 correct classifications.
At the same time, the analysis identifies clear limitations. YOLO can miss shells, crop wrong objects, or produce crops where the shell remains too small for reliable classification. Very small shells remained difficult even after preprocessing, and severe crop clipping increased the failure rate. Therefore, YOLO should not be treated as a universally safe replacement for the original image. The strongest production strategy is a dual-view approach: use both the original and YOLO-normalized predictions, accept high-confidence agreement cases, and route unresolved or risky cases to fallback handling or review.
Discussion
Principal finding: object-centric preprocessing improves operational family classification
The principal finding of this study is that YOLO-assisted object-centric preprocessing improved family-level shell classification under realistic deployment conditions. When the same user-uploaded images were processed through the standard prediction flow and through the YOLO-assisted flow, top-1 family accuracy increased from 33.4% on the original images to 44.1% after YOLO-based cropping and background normalization. Top-3 family accuracy also increased, from 52.3% to 58.0%. These gains are notable because the evaluation set was not a curated benchmark of clean shell photographs, but a temporally defined sample of real IdentifyShell uploads that included field images, cluttered backgrounds, multi-object scenes, low-quality images, non-shell objects, and invalid test uploads.
This result extends previous IdentifyShell work on family-level generalization and real-world image-domain bias. Earlier family-level modelling showed that controlled studio-like images could support strong classification performance, but that user-submitted home and field images introduced a major generalization problem because they differ in background, lighting, framing, pose, and acquisition context [15]. Earlier preprocessing in the IdentifyShell image pipeline also included attempts to isolate shells and standardize images, but those rule-based procedures were limited when faced with heterogeneous real-world uploads [14]. The present study therefore evaluates a more explicit object-centric preprocessing strategy: using a trained YOLO segmentation model to detect the shell, isolate the selected instance, crop and magnify it, and suppress the surrounding background before classification.
The image-level transition analysis gives a more informative view than the aggregate accuracy values alone. YOLO preprocessing corrected the family-level prediction in 181 images for which the original-image flow was incorrect, whereas it degraded the prediction in 52 images for which the original-image flow was correct. Thus, the net effect of preprocessing was strongly positive, but not uniformly beneficial. This supports the interpretation that YOLO should be treated as a conditional improvement to the operational pipeline rather than as a universally safe replacement for the original image.
The result is also important because the downstream family classifier was not retrained or replaced. Both the original and YOLO-transformed images were passed through the same domain-router and family-classification architecture. The experiment therefore isolates the effect of changing the image representation before classification. In this sense, the study supports the central hypothesis that a detection/segmentation stage placed before a taxonomic classifier can improve operational performance by presenting the classifier with a more shell-centred and less context-dominated input.
From a biological and taxonomic perspective, the result is consistent with the expectation that family-level shell identification should depend primarily on shell morphology rather than on acquisition context. The YOLO-assisted flow increased the relative prominence of the shell and reduced non-shell visual information, making the classifier input closer to the morphological object that a human conchologist would inspect. The remaining error rate, however, shows that object-centric preprocessing is not sufficient by itself to solve real-world shell identification. Some errors remain linked to insufficient image resolution, poor focus, partial visibility, non-diagnostic views, mislocalization, and genuine morphological similarity among families. The main conclusion is therefore not that YOLO preprocessing makes the pipeline robust in all cases, but that it provides a measurable and operationally meaningful improvement when the input distribution contains the noise typical of public user uploads.
YOLO as segmentation-assisted domain normalization under real-world domain shift
The results suggest that the YOLO-assisted flow did not merely crop the shell, but acted as a form of segmentation-assisted domain normalization. In the standard flow, the domain router classified many user-uploaded images as field-domain inputs, reflecting the presence of natural backgrounds, irregular lighting, clutter, partial occlusion, and uncontrolled framing. After YOLO-based foreground isolation and black-background replacement, many of these same images were reassigned by the router to home-like or studio-like domains. This indicates that preprocessing altered the apparent acquisition domain of the image before family-level classification.
This observation is important because it links the empirical improvement to the broader literature on natural distribution shift, shortcut learning, and background/context bias. Image classifiers are known to degrade when the test distribution differs from the training distribution, even when the semantic task is unchanged [1, 2]. Similar effects have been reported in ecological computer vision, where models trained in one environmental context can generalize poorly to new backgrounds or locations [3]. In this study, field images represent precisely such a deployment challenge: the shell remains the biological object of interest, but it is embedded in a visual environment that differs strongly from controlled training or reference imagery.
The domain-router transitions provide direct evidence for this effect. The most frequent transition after YOLO preprocessing was from field to home, and a smaller but important group shifted from field to studio. These transitions were not only cosmetic changes in router labels; they were associated with substantial classification gains. The field-to-home transition accounted for the largest net increase in correct family predictions, while field-to-studio and field-to-field transitions also contributed positive gains. This pattern suggests that much of the improvement came from suppressing field-background information before routing and family-level classification.
This interpretation is consistent with the concept of shortcut learning. Deep neural networks may exploit correlations between labels and non-causal image features, including background texture, substrate, lighting, photographic style, or acquisition setting [6]. In shell images, such shortcuts could include sand, rock, hands, labels, collection trays, or field debris. These cues may be statistically useful in a restricted dataset, but they are unreliable in a public identification system where the same family can appear across many photographic contexts. By replacing non-shell pixels and increasing the relative prominence of the shell, YOLO preprocessing physically reduces the availability of these contextual shortcuts.
The finding also extends the earlier IdentifyShell analysis of studio versus field imagery [10]. That work described studio images as controlled, centred, and minimally cluttered, whereas field images were characterized by natural backgrounds, variable lighting, occlusion, pose variation, and possible contextual bias. The present study provides an intervention-based counterpart to that analysis. Rather than only documenting that field imagery is more difficult, the YOLO-assisted flow attempts to transform field-like uploads into a more standardized object-centred representation. The observed field-to-home and field-to-studio transitions support the view that segmentation-assisted preprocessing can partially reduce the studio-to-field domain gap.
However, the results should not be interpreted as showing that background information is always irrelevant. Prior work has shown that background can sometimes function as useful signal rather than pure noise [8, 9]. In the present study, this is also suggested by the slight degradation observed for studio images after preprocessing. For field images, background suppression generally helped because the background was heterogeneous and often distracting. For already clean studio images, however, the background and lighting context may have contained useful scale, shadow, orientation, or acquisition cues. Thus, segmentation-assisted domain normalization is most useful when the original domain contains nuisance variation, but it is not a universally beneficial transformation.
Overall, the domain-transition analysis supports a central interpretation of the study: YOLO improves operational family classification primarily by changing the visual domain presented to the router and family model. The method does not create new shell morphology; instead, it reduces non-shell variation, increases object centring, and shifts many real-world uploads toward a domain that is more compatible with the downstream classifiers. This makes YOLO-assisted preprocessing a practical domain-normalization layer for heterogeneous user-uploaded biodiversity images.
Object localization, crop magnification, and fine-grained shell recognition
A second mechanism by which YOLO-assisted preprocessing improved classification was object localization and effective crop magnification. Fine-grained biological classification often depends on relatively small visual differences, and previous work in fine-grained recognition has shown that focusing the model on discriminative object regions can improve classification when class differences are subtle [11, 12]. In shell identification, relevant characters may include shell outline, spire height, aperture shape, sculpture, ribbing, colour pattern, marginal ornamentation, canal shape, and other morphological structures. If the shell occupies only a small part of the image, these diagnostic features may be diluted by surrounding background and may contribute too little to the representation learned by the downstream classifier.
The occupancy analysis supports the interpretation that YOLO preprocessing did more than remove background. It substantially increased the proportion of the classifier input occupied by the shell. Before cropping, the average YOLO bounding box occupied 28.2% of the original image area and the average mask occupied 19.1%. After padded cropping, these values increased to 64.2% and 44.2%, respectively. Thus, the YOLO-assisted flow changed the visual scale of the specimen before classification. The classifier was not only shown a cleaner image; it was shown a larger, more centred, and more morphologically dominant representation of the shell.
This crop-magnification effect was strongest in the images where YOLO helped. In cases where the original-image prediction was wrong but the YOLO-assisted prediction was correct, the mean bounding-box occupancy before cropping was only 18.2%, compared with 37.0% in cases where both flows were already correct. After cropping, the helped cases reached a mean bounding-box occupancy of 62.1%, corresponding to a large per-image magnification factor. This pattern suggests that many corrected cases were not necessarily impossible for the classifier in morphological terms; rather, the shell was initially too small or insufficiently dominant within the full image for the standard flow to extract a reliable family-level signal.
From a biological perspective, this is important because shell classification is morphology-centred. A human conchologist would normally inspect the shell itself, not the whole photographic scene. YOLO-assisted preprocessing brings the computational input closer to that mode of inspection by centring the shell and increasing its visual weight relative to non-shell pixels. The improvement is therefore consistent with the broader principle that fine-grained classification benefits when the model is directed toward the object or object parts that contain the diagnostic information [11, 12]. It is also consistent with applied biological studies where segmentation or background removal improved classification under in-situ image conditions [13].
However, crop magnification should not be interpreted as equivalent to recovering lost information. Cropping and resizing can increase the apparent size of the shell in the classifier input, but they cannot restore fine morphological detail that was absent or poorly resolved in the original photograph. This distinction is particularly relevant for very small shells, blurred images, or photographs where diagnostic features are hidden by pose, shadow, occlusion, or compression artefacts. In these cases, YOLO may correctly localize and enlarge the specimen while the resulting image still lacks sufficient taxonomic information for reliable family classification.
The localization mechanism therefore has two sides. When the original image contains a visible but under-emphasized shell, YOLO can improve classification by increasing object occupancy and reducing background competition. When the shell is already large and well centred, the marginal benefit of cropping is smaller. When the shell is extremely small or incompletely captured, magnification may produce a larger image but not a more informative one. This explains why object localization is a major contributor to the observed gain, but also why it cannot eliminate all failure modes in real-world shell identification.
This interpretation also connects with previous IdentifyShell analyses of morphology-focused CNN behaviour. The earlier Grad-CAM analysis of shell classifiers showed that model attention can correspond to biologically meaningful shell regions, including shell outline, sculpture, aperture-associated structures, shoulder features, and colour-pattern regions. Similarly, the previous studio-versus-field analysis argued that controlled specimen imagery tends to emphasize intrinsic shell characters, whereas field imagery introduces background, lighting, pose, and contextual variation that can compete with the morphological signal. The present YOLO-assisted preprocessing step can therefore be understood as a practical attempt to recover a more morphology-centred input representation from heterogeneous user-uploaded images [10, 16].
Why benefits are strongest for field and multi-object images
The strongest gains were observed in field images and multi-object images, which are precisely the image types in which the standard classification flow is most exposed to nuisance variation. Field images differ from controlled specimen photographs in several simultaneous ways: the shell may be small, off-centre, partly occluded, embedded in sand or rock, photographed under variable lighting, or surrounded by other biological and non-biological objects. These factors increase the visual distance between the user-uploaded image and the cleaner image distributions on which shell classifiers typically perform best. They also increase the opportunity for shortcut learning, because the model can respond to substrate, lighting, photographic style, or scene context rather than to shell morphology [3, 6, 7 , 10].
The field-image result therefore fits the interpretation developed above: YOLO preprocessing is most beneficial when the original image contains substantial non-shell variation. In these cases, foreground isolation and crop-based magnification reduce the amount of background presented to the domain router and family classifier, consistent with masking-based approaches that reduce background bias by suppressing non-target image regions before classification [18]. The classifier receives an image in which the shell occupies a larger proportion of the input and in which field-specific cues such as sand, algae, rocks, shadows, hands, or debris are suppressed. This explains why field images showed a much larger accuracy gain than home images and why the improvement was not simply a uniform increase across all domains.
The multi-object result reflects a related but distinct problem. Many image classifiers implicitly assume that one input image contains one main object belonging to one target class. In real user uploads, this assumption is often violated. A single image may contain several shells, a shell together with a scale object or label, or a mixture of shell and non-shell material. Under the standard flow, the classifier receives the whole scene and must infer which object is taxonomically relevant. The resulting representation may combine features from multiple specimens or from distractor objects, increasing the risk of an incorrect family prediction.
YOLO-assisted preprocessing partially changes this problem from image-level classification to instance-oriented classification. By detecting candidate shell instances and selecting a single crop for downstream prediction, the preprocessing step reduces the visual mixing that occurs when several objects are present in the same image. The observed improvement in multi-object and multi-shell images supports this interpretation. In such cases, the benefit of YOLO is not only background normalization, but also object selection: the downstream classifier is no longer forced to interpret the full scene as a single taxonomic unit.
This point is important for public biodiversity-identification systems. Citizen-science and app-based image collections are not composed only of ideal single-specimen images; they include heterogeneous scenes, variable object counts, uncertain targets, and invalid uploads [4, 5]. The earlier IdentifyShell discussion of the open-world problem made the same architectural point: a closed-world taxonomic classifier will always return a taxonomic label, even when the input is ambiguous, contains multiple possible targets, or falls outside the expected shell-image distribution [17]. YOLO-assisted preprocessing does not fully solve this open-world problem, but it reduces one important source of ambiguity by explicitly asking whether and where a shell-like object is present before classification.
The stronger gains in field and multi-object images also explain why YOLO preprocessing should be interpreted as a targeted robustness intervention rather than a general image enhancement step. The method is most useful when the original image violates the assumptions of the downstream classifier: the shell is not dominant, the background is visually complex, or more than one object competes for attention. When those violations are present, detecting and isolating the shell can substantially improve the family-level signal. When they are absent, as in many studio images, the same intervention has less opportunity to help and may even introduce unnecessary transformation. Thus, the domain-specific and multi-object results define the most appropriate operational use case for YOLO-assisted preprocessing: heterogeneous, cluttered, field-like, or multi-instance user uploads rather than already standardized specimen photographs.
Why studio images can be slightly degraded by preprocessing
The slight decrease observed for studio images is an important qualification of the overall benefit of YOLO-assisted preprocessing. Studio images already approximate the intended input condition for shell classification: the shell is usually centred, clearly visible, photographed under stable lighting, and presented against a uniform or minimally distracting background. In such images, the main nuisance factors that YOLO is designed to suppress—field clutter, multiple competing objects, poor framing, and strong environmental context—are already reduced. Consequently, the potential benefit of additional object isolation is smaller than for field or multi-object images.
This finding is consistent with the earlier IdentifyShell analysis of studio versus field imagery [10]. That analysis described studio images as controlled, object-centred, and morphology-focused, whereas field images contain variable lighting, clutter, occlusion, substrate effects, and contextual cues that can interfere with classification. The present study extends that interpretation by showing that preprocessing can be beneficial when it reduces nuisance variation, but slightly harmful when it is applied to images that are already close to the classifier’s preferred visual domain.
Several mechanisms may explain the studio-image decrease. First, cropping changes the spatial composition and scale of the image. A studio image may already contain an appropriate amount of surrounding space, shadow, and orientation context. Expanding, clipping, resizing, or re-centring the shell can alter these cues in ways that are not necessarily beneficial for the downstream model. Second, replacing the background with a flat black field removes not only distracting pixels but also potentially useful visual information, such as soft shadows, object boundaries, contrast gradients, or subtle scale and depth cues. Previous studies have shown that background information can materially affect classification and is not always pure noise [8, 9, , 19].
Third, segmentation and masking can introduce artefacts that are absent from the original studio image. Even when the shell is correctly detected, the mask boundary may slightly cut into shell margins, canals, spines, apertural edges, or fine ornamentation. Alternatively, it may create artificial high-contrast borders between the shell and the synthetic background. For shell families in which outline, aperture shape, sculpture, or marginal structures are diagnostically informative, small boundary errors can be more harmful than the original clean background. Thus, in clean specimen photographs, the preprocessing step may remove or distort information that the classifier could otherwise use.
The domain-router results also support this interpretation. Most studio images remained stable as studio-domain images after preprocessing, but a small number shifted away from the studio domain. Even for studio images that remained in the studio domain, the YOLO-transformed input was not identical to the original: the object was cropped, the background was replaced, and the pixel distribution was altered. These transformations may move an already well-formed input away from the distribution on which the classifier performs best.
This result should not be interpreted as a failure of YOLO preprocessing, but as evidence that object-centric preprocessing should be applied selectively. The method is most valuable when the original image violates the assumptions of the classifier, as in field, cluttered, or multi-object scenes. In contrast, for high-quality studio images, the safest strategy may be to retain the original image or to use YOLO only as a secondary view rather than as a compulsory replacement. The studio result therefore reinforces the broader conclusion that YOLO-assisted preprocessing is a conditional robustness tool, not a universally beneficial image transformation.
Detection errors and localization-to-classification error propagation
The results also show that YOLO-assisted preprocessing introduces a specific class of errors that differs from ordinary image-classification mistakes. In the standard prediction flow, the full uploaded image is passed directly to the domain router and family classifier. In the YOLO-assisted flow, however, classification depends first on a successful localization step. If the detector fails to find the shell, selects the wrong object, crops the specimen too tightly, or magnifies an object that was originally too small to contain sufficient diagnostic detail, the downstream classifier receives an incomplete or misleading representation. These cases illustrate localization-to-classification error propagation in a cascaded recognition pipeline.
Missed shells are the clearest example of this dependency. YOLO produced no crop in 153 images, but these no-detection cases had two different meanings. In 83 images no shell was visible, so the no-detection outcome was a useful true negative. In 70 images, however, a shell was present but not detected. These missed-shell cases are operationally important because the YOLO-assisted branch cannot produce a family prediction when no transformed crop is available. In the present paired-flow experiment no fallback to the original-image classifier was applied in such cases. Consequently, a detection failure at the first stage became a complete failure of the YOLO-assisted classification branch. This does not imply that the original image was necessarily unclassifiable, only that the preprocessing-dependent route could not continue.
Wrong-object crops represent a second, and potentially more problematic, failure mode. In these cases YOLO did produce a crop, but the crop corresponded to a distractor, background artefact, or non-target object rather than to the shell intended for classification. Unlike a missed detection, which stops the YOLO branch, a wrong-object crop can continue through the domain router and family classifier and may therefore generate a confident but biologically meaningless taxonomic prediction. The helped/hurt analysis confirms this risk: when the YOLO bounding box was reviewed as correct, preprocessing produced a strong positive net effect, but when the bounding box was reviewed as wrong, YOLO did not help and only introduced potential degradation. This indicates that most of the classification benefit depends on correct shell localization, while mislocalization mainly acts as an error source.
Very small shells form a third failure mode that cannot be solved by localization alone. YOLO can crop and enlarge a small shell region, thereby increasing its apparent size in the classifier input, but it cannot reconstruct fine morphological detail that was not captured in the original image. This is visible in the size-stratified results. Shells occupying less than 5% of the original image area showed the largest improvement after YOLO preprocessing, but they still had the highest classification failure rate. Thus, crop magnification is useful when the shell is visible but under-emphasized, yet it remains limited by the original image resolution, focus, compression, pose, and visibility of diagnostic structures. For taxonomic identification, a larger crop is not necessarily a more informative crop if the original specimen occupied too few pixels.
Crop clipping adds a fourth geometric source of risk. The preprocessing algorithm expands the YOLO bounding box by a fixed padding factor before cropping, but the padded crop must be clipped when the shell lies close to the image boundary. Minor clipping did not appear harmful and was associated with relatively good performance, but substantial clipping reduced YOLO accuracy and increased the failure rate. This suggests that severe boundary clipping can remove peripheral shell morphology, such as spines, canal extensions, margins, apertural edges, or parts of the shell outline. These structures may be important for family-level recognition. As a result, a technically correct detection can still become a poor classification input if the crop geometry truncates biologically informative regions.
These failure modes are especially important because IdentifyShell is organized as a hierarchical taxonomic pipeline. Earlier IdentifyShell work described the system as a cascade of family-, genus-, and species-level decisions. In such a hierarchy, family prediction is not merely a final label; it is also a routing decision that determines which downstream genus and species models are relevant. The family-level model work therefore emphasized that an incorrect family prediction constrains or invalidates the subsequent steps: once the image has been routed to the wrong family, the correct genus or species may no longer be available to the downstream classifier. The same principle was discussed in the open-world analysis, where inputs outside the trained scope, invalid uploads, ambiguous images, and forced closed-world predictions were identified as sources of misclassification and error propagation.
The present YOLO results extend that argument to the localization stage. In a cascaded pipeline, the detector becomes an upstream gatekeeper for the taxonomic classifier. A missed shell prevents the YOLO-assisted branch from producing a classification. A wrong-object crop turns a localization error into a taxonomic error. A very small crop may present the classifier with an enlarged but information-poor specimen. A clipped crop may remove diagnostic morphology before the family model has an opportunity to evaluate it. These are not independent errors; they are sequential dependencies. Once the upstream representation is wrong or incomplete, the downstream classifier may behave correctly with respect to the pixels it receives while still producing a wrong biological result.
The broader conclusion is that object-centric preprocessing improves robustness only when localization preserves the biologically relevant object and its diagnostic morphology. YOLO reduces background variation, isolates shell instances, and increases object occupancy, but it also creates a new upstream dependency. In a hierarchical taxonomic classifier, such upstream errors can propagate through family, genus, and species levels. The practical value of YOLO-assisted preprocessing therefore lies not only in its average accuracy gain, but in the ability to identify when the crop is reliable enough to support classification and when the system should abstain, fall back, or request a better image.
Original-versus-YOLO agreement as a confidence and triage signal
The original-versus-YOLO comparison provides a useful reliability signal in addition to its role as an accuracy comparison. The two prediction flows present different visual representations of the same uploaded image to the downstream classifier. The original-image flow preserves the full photographic scene, including background, scale, framing, and possible clutter. The YOLO-assisted flow suppresses much of this context and presents a cropped, foreground-isolated representation. When both representations lead to the same family-level prediction, the result is less dependent on a single preprocessing choice. When the two flows disagree, the prediction is more sensitive to localization, crop geometry, background removal, or the domain assigned by the router.
This pattern was visible in the agreement analysis reported in the Results. Cases where the original and YOLO-assisted top-1 predictions agreed formed a substantially more reliable subset than either complete prediction flow alone. Agreement by itself was not sufficient for automatic acceptance, because some images were consistently misclassified by both flows. However, when agreement was combined with classification-confidence thresholds, the resulting subset had very high verified accuracy. This indicates that agreement across representations can function as a practical confidence signal, especially when combined with score-based filtering.
This interpretation connects directly with the earlier IdentifyShell discussion of the open-world problem [17]. A closed-world classifier is forced to assign every input image to one of its known taxonomic classes, even when the image is poor, ambiguous, outside the trained scope, or does not contain a valid shell. The open-world analysis therefore argued that practical identification systems require rejection, fallback, uncertainty thresholds, or review rather than unconditional forced classification. The present results provide an empirical mechanism for such caution: agreement and high confidence identify a higher-trust subset, while disagreement, low confidence, missing detections, wrong-object crops, very small shells, and severe crop clipping identify cases where the system should be treated as less reliable.
The same logic is consistent with previous IdentifyShell work on human-led triage and outlier detection. In the species-delimitation workflow, embedding models were framed as structured review tools rather than automatic taxonomic authorities: their value was to prioritize candidate groups, identify stable or unstable cases, and guide expert interpretation [20]. Similarly, the outlier-analysis work used feature-space diagnostics to flag images that deviated from expected class structure because of possible mislabelling, poor image quality, atypical morphology, or other sources of mismatch [21]. The original-versus-YOLO comparison plays a comparable role in the present study. It does not prove that a family assignment is correct, but it helps distinguish predictions that are stable across visual representations from predictions that are representation-dependent and therefore more uncertain.
In a purely analytical setting, disagreement between the original and YOLO-assisted flows would be an attractive trigger for fallback or review. If the original image and the YOLO-normalized image produce different family predictions, the system could avoid automatic acceptance and instead present a lower-confidence result, request a better photograph, or route the image to manual validation. Similarly, if the YOLO detector fails, produces a low-confidence crop, or generates a crop with severe clipping or very small shell occupancy, the original full image could serve as an alternative representation. This type of dual-view strategy follows naturally from the paired evaluation, because the two flows contain complementary information: the YOLO crop reduces background and improves many field or multi-object cases, while the original image may preserve contextual or morphological information that is lost during cropping.
However, this interpretation must be separated from the operational constraints of the deployed IdentifyShell application. In production, the system will normally use only the YOLO-assisted prediction flow, because running both the original and YOLO-assisted pipelines for every upload would substantially increase response time. The current user-facing pipeline already requires a noticeable delay, and doubling the downstream classification workload would risk making the application less acceptable to users. Therefore, original-versus-YOLO agreement is best understood here as an experimental calibration signal rather than as a full online production rule.
The practical consequence is that the paired experiment should be used to design cheaper reliability rules for the YOLO-only production flow. Instead of computing agreement between two complete predictions, the deployed system can use signals already available within the YOLO-assisted path: YOLO detection confidence, number of detected instances, crop occupancy, clipping severity, classifier confidence, top-3 score distribution, and the presence of known high-risk conditions such as very small shells or no detection. These signals can approximate part of the triage information obtained from the experimental dual-flow comparison without requiring both prediction flows to be run for every user upload.
Thus, the main value of the original-versus-YOLO agreement analysis is not that it defines the exact production architecture, but that it reveals how prediction stability can be used to structure uncertainty. The results support a broader decision-support view of shell identification: high-confidence, stable predictions can be presented with greater confidence, whereas unstable or low-quality cases should trigger caution, fallback, or user feedback. This is consistent with the wider IdentifyShell strategy of treating CNN outputs as evidence for taxonomic triage rather than as final taxonomic authority [17, 20, 21].
Practical implications for IdentifyShell
The results have direct implications for the operational design of IdentifyShell. The main practical conclusion is that YOLO-assisted preprocessing should be treated as a robustness layer within the existing hierarchical identification pipeline, not simply as a generic image-enhancement step. Earlier IdentifyShell work showed that real user photographs create a major generalization problem for family-level classification because they differ strongly from controlled training or reference imagery in background, framing, lighting, object scale, and acquisition context [15]. The present results show that object-centric preprocessing can reduce part of this gap by detecting the shell, isolating the selected instance, increasing object occupancy, and suppressing non-shell visual context before family-level routing and classification. This is consistent with the broader literature on background bias and masking-based robustness, where foreground isolation can reduce nuisance variation before downstream classification [18].
From a purely analytical perspective, the strongest strategy would be a dual-view prediction design. In such a design, both the original image and the YOLO-normalized image would be classified, and the system would use agreement, confidence, and crop-quality information to decide whether to accept the result, fall back to another representation, or request review. This approach is attractive because the two representations contain complementary information. The original image preserves the full photographic scene, including scale, orientation, and context, while the YOLO-assisted image reduces background clutter and often improves field and multi-object cases. The agreement analysis in this study shows that prediction stability across these two representations can identify a more reliable subset of cases.
However, this dual-view strategy is not the current production design, and it is not necessarily practical for a public user-facing system. The current IdentifyShell prediction flow already requires a noticeable response time, typically on the order of 15–45 seconds. Running both the original and YOLO-assisted flows for every upload would substantially increase latency and computational cost. In a public application, this additional delay may not be acceptable to users, especially when the identification process already involves multiple downstream steps in a hierarchical classifier. Therefore, although dual-view prediction is valuable for evaluation and calibration, the deployed production system should normally use the YOLO-assisted prediction flow alone for operational reasons.
The practical challenge is therefore to transfer the lessons from the paired experiment into a faster YOLO-only production workflow. Confidence-gated acceptance is the most direct mechanism. The deployed system can use signals already available within the YOLO-assisted flow, including YOLO detection confidence, number of detected instances, crop occupancy, crop clipping severity, classifier confidence, top-3 score distribution, and top-1 versus top-2 margin. High-confidence detections with strong classifier support can be presented more confidently, whereas low-confidence detections, weak classification margins, multiple competing objects, very small crops, or severe clipping should be treated as lower-reliability cases. This follows the safety logic of the earlier open-world analysis: the system should avoid treating every closed-world prediction as equally trustworthy when the input may be ambiguous, invalid, low quality, or outside the trained scope [17].
A fallback to the original image would be a logical extension when YOLO fails, but this is not part of the current implementation. In the paired experiment, no-detection cases were retained as “no YOLO crop available” rather than being replaced by an original-image prediction. In a future production version, missed-shell cases could trigger automatic fallback to the original-image flow, while true no-shell cases could trigger a no-object response or user feedback. This would reduce the risk that a failed localization step prevents classification entirely. Nevertheless, such fallback should be presented as a future improvement rather than as a current feature, because the present production implementation is designed around the YOLO-assisted route.
The same distinction applies to wrong-object crops. A wrong-object detection is more dangerous than a missed detection because it can continue through the taxonomic classifier and produce a plausible but biologically meaningless family prediction. In future versions, wrong-object risk could be reduced by combining YOLO confidence, crop size, mask shape, classifier confidence, and possibly a separate shell-versus-non-shell validation step. For now, the practical conclusion is more conservative: predictions derived from low-confidence or visually suspicious crops should be flagged as less reliable, and the user should not be given the impression that all YOLO crops are equally trustworthy.
User feedback is therefore an important part of the operational pipeline. Very small shells remained difficult even after preprocessing, because cropping can magnify the object but cannot recover fine morphological detail that was not captured in the original image. Poor focus, compression artefacts, partial visibility, non-diagnostic views, and extreme scale reduction remain limiting factors. The current application already provides feedback for poor-quality or very small-shell images, and the present results support strengthening this behaviour. When the detected shell occupies only a very small proportion of the image, or when the crop is severely clipped or low confidence, the system should ask the user for a closer, sharper, better-centred photograph rather than presenting the prediction as robust.
These practical implications also reinforce the hierarchical structure of IdentifyShell. Family prediction is the first major taxonomic routing decision, and an incorrect family result constrains all downstream genus- and species-level decisions [14, 15]. YOLO-assisted preprocessing improves the input representation for many difficult images, but it also creates an upstream localization dependency. A missed shell, wrong-object crop, very small crop, or clipped crop can therefore affect not only family-level accuracy but the entire downstream taxonomic path. For this reason, detection quality should be treated as part of the taxonomic decision process rather than as a hidden preprocessing detail.
Overall, the recommended operational interpretation is conditional rather than absolute. YOLO-assisted preprocessing is valuable because it improves robustness on heterogeneous, field-like, and multi-object uploads, which are precisely the inputs that challenge a public identification system. At the same time, it should not be described as a universally safe replacement for original-image prediction. In production, operational latency makes a full dual-view strategy difficult, so the most realistic path is a YOLO-first workflow supported by confidence gates, crop-quality checks, and user feedback. The long-term architecture can then evolve toward selective fallback or review for high-risk cases, while preserving acceptable response times for ordinary users.
Limitations and future work
This study has several limitations that should guide future development of the IdentifyShell pipeline. First, the evaluation was based on a temporally defined sample of real user uploads rather than on a fully balanced taxonomic benchmark. This was intentional, because the purpose of the study was to evaluate operational behaviour under realistic deployment conditions. However, it also means that the dataset reflects the uneven composition of public uploads: some shell families, photographic domains, object sizes, and image-quality categories are better represented than others. Consequently, the reported performance should be interpreted as deployment performance for this particular user-upload distribution, not as a taxonomically balanced estimate of family-level recognizability across all Mollusca.
A second limitation is class imbalance and heterogeneous morphology. Molluscan families differ strongly in external shell form, diagnostic visibility, intra-family diversity, and similarity to other families. Some families contain visually distinctive morphologies, whereas others overlap strongly in outline, sculpture, colour pattern, or general shell habit. Previous IdentifyShell work on intra- and inter-class variability showed that CNN performance is affected by feature-space overlap, outliers, atypical morphology, and variable image quality [21]. The present YOLO-assisted preprocessing step can reduce background and scale variation, but it cannot eliminate genuine biological or morphological overlap between families. When families are visually similar or internally heterogeneous, downstream classification remains difficult even if the shell has been correctly localized.
This limitation is especially relevant for hierarchical classification. IdentifyShell does not operate as a single flat label assignment, but as a taxonomic cascade in which family-level prediction determines the downstream genus- and species-level route [14, 15]. The present study evaluated the YOLO intervention primarily at family level, because family prediction is the first major routing decision. Future work should therefore test whether the observed family-level gains also translate into more reliable genus- and species-level predictions, especially for families with complex internal morphology or unevenly represented genera.
A third limitation concerns label noise and review uncertainty. The evaluation used manual review to determine whether the standard and YOLO-assisted family predictions were correct, but it did not create a fully re-annotated expert benchmark for every uploaded image. Some user uploads are intrinsically difficult to verify because of poor focus, partial visibility, non-diagnostic views, juvenile shells, damaged specimens, or images showing multiple possible targets. In such cases, the distinction between model error, image inadequacy, and taxonomic uncertainty is not always sharp. Future evaluations should incorporate a more explicit uncertainty category, multiple expert reviewers for ambiguous cases, and separate analyses of image-quality failure versus taxonomic confusion.
A fourth limitation is that the YOLO model itself was trained as a single-class shell detector on a limited annotated dataset. This design is appropriate for testing whether object-centric preprocessing improves classification, but it does not fully solve the open-world problem. The detector may miss shells, crop the wrong object, or select the wrong specimen in multi-object images. It also does not distinguish between different shell types, views, preservation states, or invalid shell-like objects. Future detector training should therefore include more hard negatives, more multi-object scenes, more very small shells, and more examples from the same operational upload distribution. Additional detector outputs, such as shell-versus-non-shell confidence, mask quality, crop completeness, and object-size warnings, could be used as reliability signals before classification.
A fifth limitation is that the current preprocessing uses a fixed crop-padding strategy and uniform black background replacement. These choices make the experiment reproducible and easy to interpret, but they may not be optimal for all image types. Very small shells remained difficult even after cropping, indicating that magnification cannot recover fine morphological detail lost in the original image. Substantial crop clipping also increased the failure rate, suggesting that the crop geometry can remove biologically informative shell margins or apertural structures. Future work should test scale-aware padding, boundary-aware crop expansion, softer background suppression, background blurring instead of complete replacement, and higher-resolution crop handling for very small shells.
The production implementation also imposes operational constraints. The paired design used in this study is valuable because it compares original-image and YOLO-assisted predictions for the same upload, but running both flows in production would increase response time substantially. The current user-facing application already has a noticeable latency, so a full dual-view workflow may not be acceptable for routine use. Future work should therefore focus on lightweight reliability proxies available within the YOLO-only flow, including YOLO confidence, crop occupancy, clipping severity, number of detected instances, classifier confidence, top-3 score distribution, and top-1 margin. These features could support confidence-gated acceptance without requiring two complete downstream prediction pipelines.
Finally, the results should be interpreted within a decision-support framework rather than as automatic taxonomic authority. The species-delimitation work framed embedding-based models as tools for human-led triage, stability assessment, and expert review rather than as final arbiters of species boundaries [20]. The same principle applies here. YOLO-assisted preprocessing can improve the quality of the image representation and increase family-level accuracy, but uncertain predictions, ambiguous morphology, out-of-distribution inputs, and low-quality images still require caution. Future versions of IdentifyShell should therefore combine improved preprocessing with uncertainty-aware triage: confident cases can be returned automatically, while low-confidence, unstable, very small, clipped, or suspicious cases should trigger fallback, user-facing image-quality feedback, or expert review.
Overall, future work should move in three directions. First, the detector should be trained and validated on a larger, more diverse operational dataset, with explicit attention to hard negatives, small shells, multi-object images, and boundary cases. Second, the classification pipeline should be evaluated beyond family level to determine how YOLO-assisted preprocessing affects genus- and species-level routing accuracy. Third, the production system should integrate confidence gates and image-quality feedback so that the model can distinguish between images that are suitable for automatic identification and images that require a better photograph, fallback processing, or human interpretation. These steps would preserve the practical benefit of object-centric preprocessing while reducing the risk of overconfident classification in cases where the image or taxonomy remains uncertain.
References
- [1] B Recht et al. Do ImageNet Classifiers Generalize to ImageNet?. In Proceedings of the 36th International Conference on Machine Learning, PMLR 97, 5389–5400. arXiv:1902.10811. (2019)
- [2] R Taori et al. Measuring Robustness to Natural Distribution Shifts in Image Classification. In Advances in Neural Information Processing Systems, 33, 18583–18599. arXiv:2007.00644. (2020)
- [3] S Beery, G Van Horn, & P Perona. Recognition in Terra Incognita. In Proceedings of the European Conference on Computer Vision (ECCV), 456–473. doi:10.1007/978-3-030-01270-0_28. (2018)
- [4] G Van Horn et al. The iNaturalist Species Classification and Detection Dataset.. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8769–8778. (2018)
- [5] G Van Horn et al. Building a Bird Recognition App and Large Scale Dataset With Citizen Scientists: The Fine Print in Fine-Grained Dataset Collection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 595–604 (2015)
- [6] R Geirhos ei al. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2, 665–673 (2020)
- [7] K K Singh et al. Don’t Judge an Object by Its Context: Learning to Overcome Contextual Bias. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11070–11078 (2020)
- [8] K Y Xiao et al. Noise or Signal: The Role of Image Backgrounds in Object Recognition. International Conference on Learning Representations (ICLR) (2021)
- [9] M Moayeri et al. A Comprehensive Study of Image Classification Model Sensitivity to Foregrounds, Backgrounds, and Visual Attributes. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 19087–19097 (2022)
- [10] Ph Kerremans Impact of Studio versus Field Imagery on CNN Performance for Mollusc Shell Analysis. IdentifyShell (2025)
- [11] J Fu, H Zheng & T Mei. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4438–4446 (2017)
- [12] X-S Wei et al. Mask-CNN: Localizing parts and selecting descriptors for fine-grained bird species categorization. Pattern Recognition, 76, 704–714 (2018)
- [13] K KC Kamal et al. Impacts of Background Removal on Convolutional Neural Networks for Plant Disease Classification In-Situ. Agriculture, 11(9), 827 (2021)
- [14] Ph Kerremans Optimizing Molluscan CNN Taxonomy: Balancing Hierarchy Simplification, Data Volume, and Augmentation for Improved Classification. IdentifyShell (2025)
- [15] Ph Kerremans Building a New Family-Level Model: Why Generalization Matters. IdentifyShell (2025)
- [16] Ph Kerremans Unveiling Morphological Insights in Biological Imagery Through CNN Interpretability Techniques. IdentifyShell (2025)
- [17] Ph Kerremans Coping with the open-world problem when identifying Mollusca. IdentifyShell (2025)
- [18] A Aniraj ey al. Masking Strategies for Background Bias Removal in Computer Vision Models. Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2486–2495 (2023)
- [19] J Liang, Y Liu, & V Vlassov The Impact of Background Removal on Performance of Neural Networks for Fashion Image Classification and Segmentation. . Proceedings of the 2023 Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE), pp. 323–331. (2023)
- [20] Ph Kerremans Species Delimitation as Human-Led Triage: A Stability-Aware Embedding Benchmark with COX1 Validation in Cone Snails (Gastropoda: Conidae) from Maio, Cape Verde. IdentifyShell (2026)
- [21] Ph Kerremans Analyzing Intra- and Inter-Class Variability and Detecting Outliers in CNN Seashell Image Classification Models. IdentifyShell (2025)